本文由来,有一个需求要在浏览器输入Kafka topic,消费组提交后自动开启消费,这个做起来比较简单,同事使用了Kafka 驱动包很快速完成这个。我突然想到能不能通过Spring Kafka自身框架完成这个功能,不使用底层驱动包来自做呢。而引出分析整个Spring Kafka 如何实现注解消费信息,调用方法的。并且最后通过几个简单的代码完成上面小需求。
源码解析
EnableKafka入口
kafka 模块的开始先从@EnableKafka 上@Import(KafkaListenerConfigurationSelector.class)
1 |
|
接着继续看下KafkaBootstrapConfiguration类
1 | public class KafkaBootstrapConfiguration implements ImportBeanDefinitionRegistrar { |
使用BeanDefinitionRegistry 将class 转换成beanDefinition,注册到beanDefinitionMap 容器中,容器会统一将Map Class全部进行实例化,其实就是将这个交给Spring 初始化。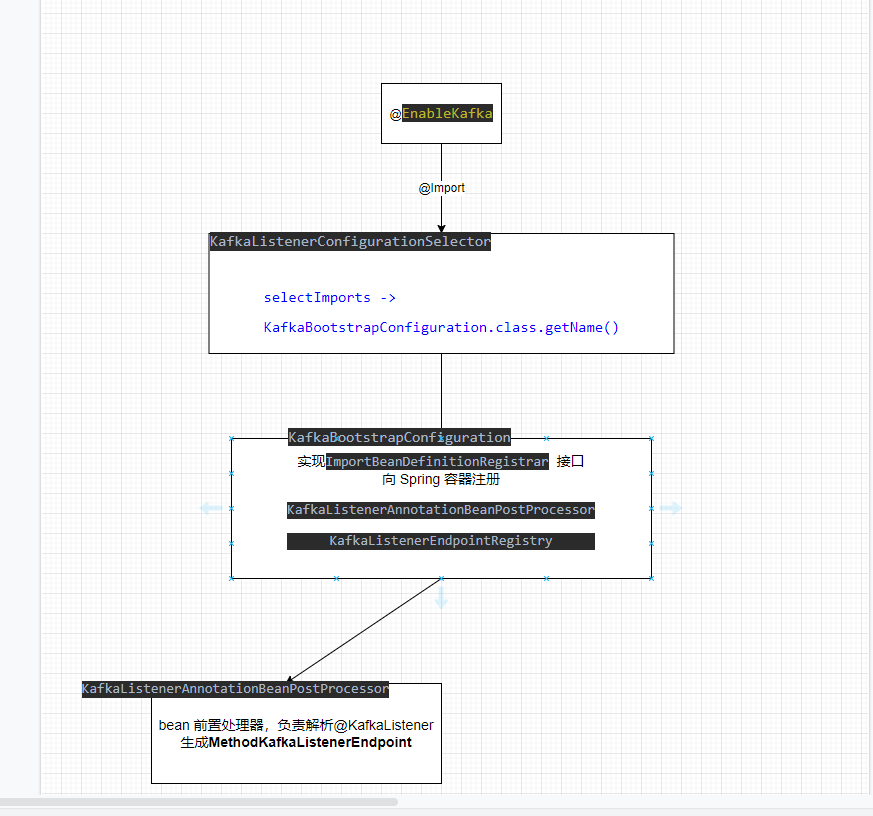
KafkaListenerAnnotationBeanPostProcessor 解析
下面看下kafka核心处理类KafkaListenerAnnotationBeanPostProcessor 如何解析@KafkaListener 注解,postProcessAfterInitialization 在bean 实例化后调用方法,对bean 进行增强。
1 | public Object postProcessAfterInitialization(final Object bean, final String beanName) throws BeansException { |
@kafkaListener其实可以作用于Class 上的,搭配着@KafkaHandler一起使用,那怎么样使用呢,我用一个简单例子展示下。
1 | (topics = "${topic-name.lists}",groupId = "${group}",concurrency = 4) |
消费信息不同对象区分进行处理,省去对象转换的麻烦,我暂时想到场景就是这些,平常很少有这些。这个实现原理我就不深入分析了
1 | protected void processKafkaListener(KafkaListener kafkaListener, Method method, Object bean, String beanName) { |
类名MethodKafkaListenerEndpoint 都可以理解成端点对象,简单地说,端点是通信通道的一端。可以理解这个端点连接业务方法和kafka 信息之间的通信端点。
@RetryableTopic 是spring kafka 2.7 后出的一个注解,主要作用就是在消费kafka信息时出现消费异常时,失败重试而出现死信信息的处理,由于Kafka内部并没有死信队列或者死信信息这类东西。Spring 自己搞出来一个DLT topics (Dead-Letter Topic),意思就是当消费信息失败到达一定次数时,会将信息发送到指定DLT topic 中。注解可以设置重试次数、重试时间、故障异常、失败策略等等。
其实这个processMainAndRetryListeners 方法跟下面processListener 作用差不多,都有解析注解内容,然后调用KafkaListenerEndpointRegistry.registerEndpoint 方法。
KafkaListenerEndpointRegistry 主要由Spring 容器创建,用于实例化MessageListenerContainer
KafkaListenerEndpointRegistrar主要代码new创建,并没有交给spring容器管理,用于帮助bean 注册到KafkaListenerEndpointRegistry中
这个两个类类名特别相似,在分析源码时被搞到晕头转向,分清楚后其实就挺简单了,这个类名搞混上浪费不算时间去理解。
注册endpoint
1 | public void registerEndpoint(KafkaLiEstenerEndpoint endpoint, @Nullable KafkaListenerContainerFactory<?> factory) { |
这里为什么有一个startImmediately开关呢,这里只是将endpoint 放入容器集中保存起来,等到全部添加完成后,使用Spring InitializingBean接口afterPropertiesSet 方法进行基础注册启动,这是利用了Spring bean 生命周期方法来触发,如果是Spring 完全启动完成后,那添加进来endpoint就是不能启动的了,所以相当于一个阈值开关,开启后立即启动。
下面看下调用KafkaListenerEndpointRegistrar.afterPropertiesSet 来开启各大endpoint 运行。
1 |
|
MessageListenerContainer
看下KafkaListenerEndpointRegistry.registerListenerContainer 方法如何生成信息监听器的。
1 | public void registerListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory) { |
主要就是通过KafkaListenercContainerFactory 信息监听工厂来创建监听器MessageListenerContainer ,通过继承了SmartLifecycle。SmartLifecycle接口是Spring 在初始化完成后,根据接口isAutoStartup() 返回值是否实现该接口的类中对应的start()。Spring 当spring 完全初始化完成后,SmartLifecycle 接口就不会被Spring 调用执行,这时就需要手动执行start 方法,所以startIfNecessary 方法才会判断容器已经启动完成了。
MessageListenerContainer
1 | public C createListenerContainer(KafkaListenerEndpoint endpoint) { |
这时kafka 配置信息、@KafkaListener 信息、消费方法、bean 已经全部设置createListenerContainer,这时监听器容器就可以启动kafka 拉取信息,调用方法进行处理了。
直接从信息监听器ConcurrentMessageListenerContainer启动方法开始
1 | public final void start() { |
看到了@KafkaListener 并发数如何实现的,并且并发数不能超过分区数的,如果并发数小于分区数,则会出现平分的情况,可能会让一个消费占有多个分区情况。这里在创建KafkaMessageListenerContainer 去对Kafka topic 进行消费。
KafkaMessageListenerContainer
因为KafkaMessageListenerContainer和ConcurrentMessageListenerContainer都是通过extends AbstractMessageListenerContainer 重写doStart()开启任务,直接看见doStart就可以知道程序入口了。
1 | protected void doStart() { |
pollAndInvoke 这个方法就是拉取信息和处理的过程了,方法太繁琐了,无非就是如何去调用endpoint 生成信息处理器,并且将参数注入方法中。
总结
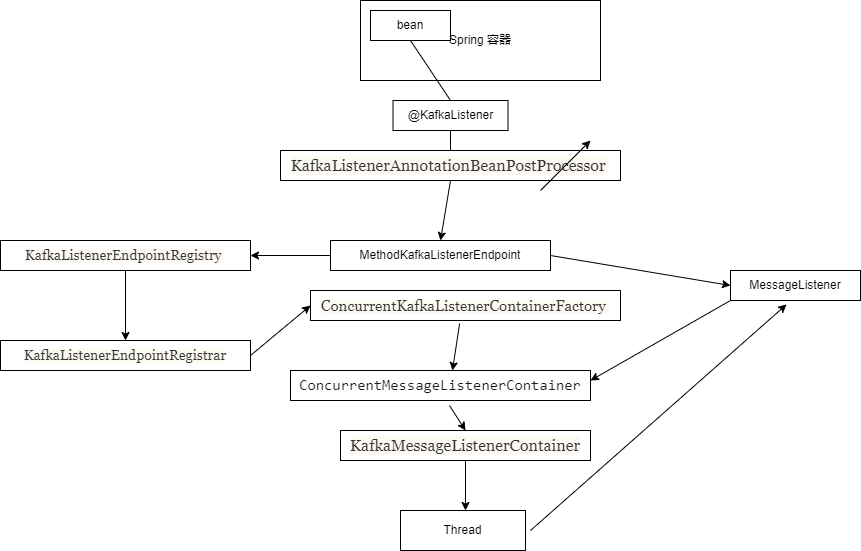
结合上面图,简单总结下Spring Kafka 如何通过一个简单注解实现对方法消费信息的。首先通过Spring 前置处理器机制使用KafkaListenerAnnotationBeanPostProcessor 扫描所有已经实例化的bean,找出带有@KafkaListener bean 和方法,解析注解的内容设置到MethodKafkaListenerEndpoint,并且注册到KafkaListenerEndpointRegistry,有它统一保存起来,等到执行前置处理器统一将KafkaListenerEndpointRegistry保存起来的enpoint,注册到KafkaListenerEndpointRegistrar,根据enpoint生成ConcurrentMessageListenerContainer,在根据并发数去生成对应数量的KafkaMessageListenerContainer,最后使用Thread 异步启动Kafka 信息拉去,调用bean 方法进行处理。
还理解了topic 分区和并发数如何关联的,还知道kafka消费是可控制的,处理Kafka信息方法,返回值可以被推送到另一个topic的、也是第一次知道有@RetryableTopic 重试机制,还有DLT 死信topic。如果不是看源码分析,平常工作场景估计很少用得上这些。现在看源码多了,越来越有感觉查看代码更能加深你对框架学习,心得。
动态订阅
看了这么多代码,对照处理器CV下就,简单版动态监听就可以实现了
1 |
|
我们看过完整代码,知道监听动作是由KafkaListenerContainerFactory创建后,调用实例start 方法开始的,并且我们还能拿到监听容器对象,可以调用对象各式API,可以动态停止对topic消费哦。
1 |
|
这个简单http接口,通过接口方式支持对外扩容的方式动态订阅频道,并且支持已经订阅topic消费停下来。
使用@kafkaListener 声明方法消费的同学不用羡慕的,Spring 提供机制可以去获取MessageListenerContainer,上面代码分析我们知道了KafkaListenerEndpointRegistry内部的listenerContainers 会保存所有container实例,并且提供外部方法根据id去获取对象,而且KafkaListenerEndpointRegistry还是有spring 进行实例化的,所以….
为了方便获取id简单,可以在使用注解时,手动指定id 值,如果没有指定则id,默认生成规则是org.springframework.kafka.KafkaListenerEndpointContainer# + 自增长
SpringBoot 自动配置
大家可能好奇,Spring boot中Kafka配置信息如何给kafkaListenerContainerFactory,因为它是通过Spring 容器初始化的,源码中并没有看见带有构造器的参数注入。想要具体了解,只有看KafkaAnnotationDrivenConfiguration,ConcurrentKafkaListenerContainerFactoryConfigurer
1 | (proxyBeanMethods = false) |
作为其实Spring Boot自动配置原理就是由spring-boot-autoconfigure 包编码实现的,在根据@ConditionalOnClass 注解来决定是否启动配置类,所以当你引入对应pox时,就会启动配置类了,配置信息会注入到KafkaProperties对象中,然后将properties 设置到工厂对象,实例化对象交给spring 容器,你会发现大多数自动注入都是这样套路。