如果想更详细了解ConcurrentHashMap 内部工作原来可以去看下我以前写过一篇HashMap源码解析了解下hash 算法原理、数组扩容、红黑树转换等等。
initTable
1 | private final Node<K,V>[] initTable() { |
这个是初始化map数组,核心是sizeCtl 这个变量:一个使用volatile修饰共享变量,作用通过交换比较竞争获取初始化或者扩容数组执行权。当线程发现sizeCtl小于0的时候,线程就会让出执行权,当线程成功竞争设置-1 就相当于获取到执行权,所以就可以去初始化数组了。当为正数时,保存下一个要调整Map大小的元素计数值
说明下Unsafe 交换比较方法
1 | /** |
put方法解析
1 | public V put(K key, V value) { |
简单说下put 业务逻辑:
先判断table数组是否为空,不加锁,调用initTable 进行初始化
计算key 哈希值,通过hash计算出数组中下标,如果下标刚好为空,通过交换比较设置进去。多个线程设置通过数组下标时,当设置失败时会不满足下标为空情况,进入获取头节点锁
此时节点有值,并且hash 值等于-1,则说明数组正在扩容,调用helpTransfer 方法多线程进行copy数组
只锁住链表或红黑树根节点,先判断根节点是否等于获取锁的对象,因为有可能获取到锁对象已经因为数组扩容进行偏移了 ,如果已经进行偏移还在根节点进行插入会导致hash计算错误,导致get 获取不到值。这个是安全检查很重要的。
为什么要判断fh >= 0 主要是因为ConcurrentHashMap Node hash 有特殊意义
- int MOVED = -1; 正在进行数组扩容,准备迁移
- int TREEBIN = -2 红黑树根节点
- int RESERVED = -3; 临时保留节点
大于0就知道这是一个链表,从头开始遍历到最后插入,Java8 链表改成尾插入有一个好处就是遍历完链表后就知道链表长度了,binCount就是链表长度。每次遍历节点都会比较key相等,覆盖旧值,否则在链表最后插入。
红黑树逻辑插入和链表差不多,通过putTreeVal 遍历并且插入节点,只要找到相同key节点才会返回节点对象,如果是在红黑树下新增只会返回null。
binCount是链表长度,如果长度大于链表长度阈值(默认8)转换成红黑树。因为上面遍历时遇到相同key值,都会将节点赋值给oldVal,如果不为空则是覆盖,不需要执行累加,直接返回就可以了。
addCount只要就是对map size进行累加,因为在并发情况下不能直接加锁住size方法进行加一,这违反设定的粗细粒锁的设定。实际情况比较复制,数组扩容的逻辑也是在这个方法中实现的,下面具体分析下。
size() 方法
在分析map size之前,看讲下size方法如何获取长度,有利于addCount 讲解。
1 | public int size() { |
size长度主要是通过baseCount + CounterCell数组累加起来的。baseCount 只要当一个线程在使用map时,才会使用baseCount来记录size大小,当出现多个线程线程同时对map操作时,就会放弃使用baseCount,而将每个线程操作数量 放入CounterCell数组中。可以理解CounterCell只是一个计算盒子,通过一些算法将不同线程操作数量放入到指定index位置,可以隔离线程对同个数竞争修改,有点类似hash 计算下标放入数组方式,这样可以减少冲突次数。
addCount分析
1 | private final void addCount(long x, int check) { |
先从if判断开始,如果countCells 这个数组不空,第二个条件不用判断,进入countCells设置累加。第一个条件不成立就会执行 baseCount累加,累加成功条件不成立,不进入if逻辑。
countCells 初始化、x值添加到数组上,或者多线程对同一个数组下标累加的控制都需要fullAddCount去实现的。
上面说过sizeCtl 为正整数就是数组容量扩容阈值,while 下先判断map size 是否达到或者超过阈值,符合条件就会
进入循环了进行数组扩容。当sizeCtl > 0 时则是多个线程在对数组扩容,这时需要竞争获取执行权。
具体分析下扩容条件如何成立的,首先直到
resizeStamp(n) << RESIZE_STAMP_SHIFT;
这个方法是将数组n,低位补零左移16为,相当于讲数组长度保存到高16位中。每一个线程参与并发就会在sizeCtl 上+1 ,低16位这样就是用来保存参与数组扩容数量。
sc > 0
- 这时还没有线程对tab数组进行扩容
sz < 0
- 已经有线程在扩容,将sizeCtl+1并调用transfer()让当前线程参与扩容。
下面分析下while 里面的判断
- sc == rs + MAX_RESIZERS 当前线程数已经达到最大上限了,再有新的线程进来扩容就没有意义了
- sc == rs + 1 只要rs + 1成功会在调用transfer,但是现在rs值已经被其他线程修改了,累加已经失败了,没有必要在执行一次交换比较了。
- (nt = nextTable) == null 此时扩容已经完成了,新的线程不必进入扩容方法了
- transferIndex <= 0 transferIndex tab数组没有分配的迁移的数量,此时为0表示扩容线程已经达到最大数量了,不必再使用新的线程进入了
细讲下fullAddCount 方法
ThreadLocalRandom.getProbe()可以简单理解成每一个线程hash值,但是这个值不是固定的,在找不到数组slot是,可以重新计算。
1 | private final void fullAddCount(long x, boolean wasUncontended) { |
cellsBusy 这个属性跟我们之前讲过sizeCtl 功能很相识的,都是来控制数组修改权限的。当cellsBusy =0时,counterCells数组可以被插入、扩容的 ,线程只要将cellsBusy设置成1就可以获取修改权限,改完后将cellsBusy变成0就可以了。
看过LongAdder源码的同学是不是觉得很熟悉啊,不能说很相识,只是说是一模一样,就连变量名都是复制过来的。其实这个我愿意讲这个细节的原因,涉及了LongAdder设计思想,value值分离成一个数组,当多线程访问时,通过hash算法映射到其中的一个数字进行计数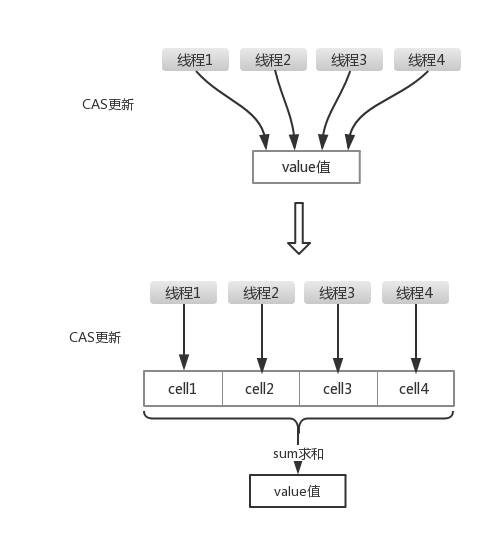
transfer
接着看下map在多线程下如何进行扩容的
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
ForwardingNode 这个是一个特殊节点,在数组迁移过程中,已经被迁移过去节点会被标注成这个对象。防止在迁移数组过程中插入到旧数组中。内部封装一个find方法,可以去新数组中查找key value,下面get方法会用到的。
如何支持并发情况下,分配各个线程任务的。每一个线程进入都会在双层循环的while中分配到任务。刚进来时前面两个if、else if不会满足条件,但是会讲transferIndex重新赋值给nextIndex,此时nextIndex还是数组长度来的,当开始竞争修改transferIndex 时,设置成功的线程,分配到了数组下标 tab.leng -1 到 tab.length -1 - stride 这个范围的下标,从数组最后往前进行元素分配,并且将迁移完成index设置bound,i为数组copy的下标,当下标已经迁移到下个线程开始位置时,就会跳出while循环了,否则每次进入while就为了让下标 -1。竞争失败的线程会重新进入whle循环,继续去从transferIndex获取分配数量。当transferIndex不为空时,表示数组仍然有任务分配,继续去竞争获取。
if (i < 0 || i >= n || i + n >= nextn) { 当i < 0 成立时表示当前线程已经做完copy任务了, i >= n || i + n >= nextn都是跟下面i = n 相关,对当前数组进行边界检查。我们上面说过sizeCtl低16位表达当前线程扩容数量,让一个线程完成任务后,在sizeCtl -1 。sizeCtl -2 不相等主要和扩容时sizeCtl +2 调用transfer 向对应,不相等说明此时仍然有其他线程正在copy中,扩容没有完成的,已经完成线程自动退出扩容方法。让最后一个线程将完成收尾工作,将nextTab 变成tab。
get方法
1 | public V get(Object key) { |
get方法没有使用锁,支持最大并发读取,而且不会出现安全问题。当eh < 0 ,这时是红黑树的话,调用红黑树遍历方法去操作节点。如果此时ForwardingNode,虽然这个节点的数据已经被迁移到新数组去了,但是内部封装find方法,去新的数组中查找。无论是哪种节点都可以找到对应key value。
删除方法
1 | public V remove(Object key) { |
资料引用
https://xilidou.com/2018/11/27/LongAdder/