以后面试官问你HashMap原理,不能再答数组+链表的结构了,
JDK1.8添加了红黑树结构,知识要与时俱进啊。受限于文章篇幅,我会从HashMap 初始化,put、get、remove方面解析底层原理。
内部设定
常量设定
1 | /** |
内部元素结构
1 | static class Node<K,V> implements Map.Entry<K,V> { |
Node对象只拥有三个属性,key,value,next,结构非常简单,操作也简单。
内部属性变量
1 | /** |
解析代码
构造函数
1 | public HashMap(int initialCapacity, float loadFactor) { |
这段代码很简单,主要是判断两个输入参数是否合法,将容器长度重新计算扩容阈值。
看下tableSizeFor怎么计算阈值
1 | /** |
这个方法其实通过输入数,返回一个最接近大于等于他的2次方数。
通过将cap 高位1不断右移,返回cap最近2次方的数。如果有同学看不懂这个算法,可以参考这位老哥写的https://blog.csdn.net/fan2012huan/article/details/51097331,解析得非常易懂。
上面的构造函数,并没有初始化Node 数组,我进入put方法看下怎么样初始化的!
添加元素
1 | public V put(K key, V value) { |
整体流程: 先判断数组为空,没有则使用resize()方法初始化数组,使用hash 值& 数组长度计算下标,下标值为空,直接插入。处理hash冲突情况,先判断链头key是否相等,判断数组Node是否树链,则使用putTreeVal方法插入树链中,否则遍历链表在结尾插入。最后判断数组元素是否超过阈值,使用reszie()扩容。这个流程基本和我们平常写业务代码差不多。
计算hash方法
1 | static final int hash(Object key) { |
假设没有这个hash算法,对象hashCode直接&数组长度(n-1),当n比较小的时候,hash虽然是32位整数,但是只要低位是有效的,hash冲突概率比较大,会导致链表比较长。使用hash方法将高16位影响到低16位,将低16位的二进制打散了,减少了hash冲突概率。resize扩容,初始化数组方法
1 | final Node<K,V>[] resize() { |
整体流程还是比较简单的,先确定数组长度,threshold属性,创建新数组移动copy元素,删除原数组元素。这个方法基本就是初始化table数组,扩容数组,处理链条或树链的内部细节。if ((e.hash & oldCap) == 0) { 这个写法,看了好久才明白什么意思啊。我们都知道数组长度永远都是2的次方,二进制表现就是最高位是1 其他都是0, 比如默认长度16 ,二进制就是10000。 计算数组长度算法e.hash & (oldCap- 1), 长度-1 二机制的数1111,先数组扩容长度 * 2,计算下标结果下标前面不变,最高位是0还是1,是0保存下标不变,是1表示下标需要x 2.。觉得讲得不清楚,可以看下图
下面了解拆分树链的split
1 | /** |
首先要知道TreeNode间接继承Node,拥有单向链条的属性。理解上面流程就很简单了,先遍历树链,按照hash & 数组长度方式,分成移动下标和不移动两个类型树链。再判断链条数量是否大于UNTREEIFY_THRESHOLD(6) ,满足使用untreeify方法拆分成链条。如果树链头不为空,则说明红黑树结构依然存在,使用treeify方法将链表转换成树链。
要理解链表怎么转化成树链,必须深入treeify方法
1 | final void treeify(Node<K,V>[] tab) { |
看到这里,大家是不是跟我一样,觉得代码写得还是比较简单的,没什么难度啊。下面代码就不是这样了,没有一点黑红树基础的同学,麻烦先补下课先,不然你很难理解代码什么意思。
红黑树的性质
- 节点是红色或黑色。
- 根节点是黑色。
- 所有叶子都是黑色(叶子是NIL节点)
- 每个红色节点的两个孩子节点必须是黑色. (从叶子到根的所有路径上不能有两个连续的红色节点)
- 从任意节点到其叶子节点的所有路径都包含相同数目的黑色节点。

在红黑树插入或删除情况,上面的特征可能会被打破。所以要使用balanceInsertion方法平衡树链结构。我们在分析代码的时候,一定要把上面5个性质带上有助于理解。
1 | static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, |
上面的代码配合这三个图片,看出1-3 处理完后,刚好是图1-1 处理条件,向上递归,直到终止循环。这个就是插入后,调整红黑树平衡整体流程。这些代码,我当时看了一整天也明白什么意思,后面结合红黑树知识,自己画图对应代码流程,理解起来就很简单了。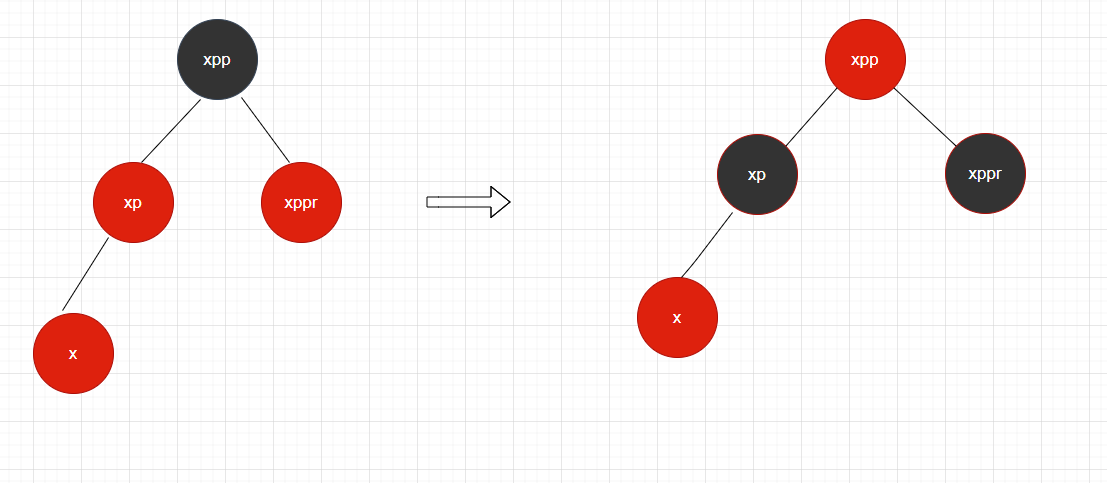
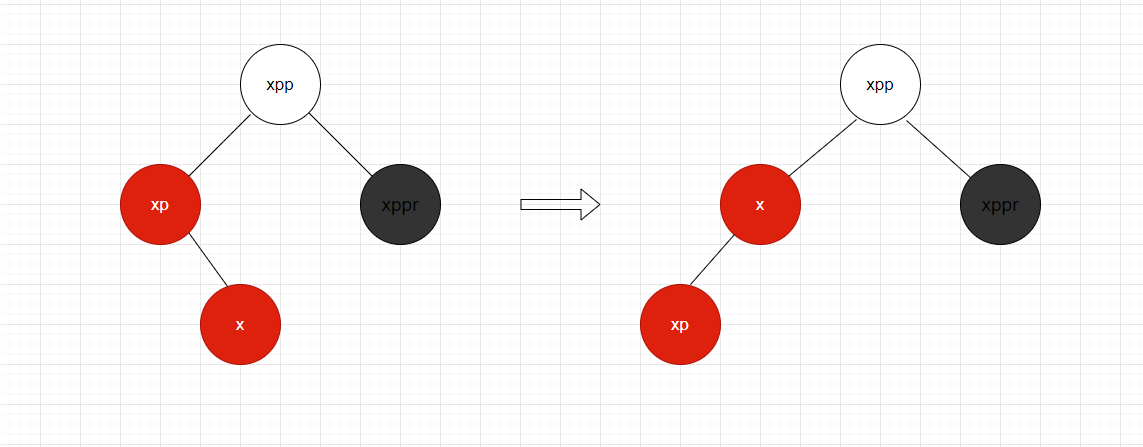
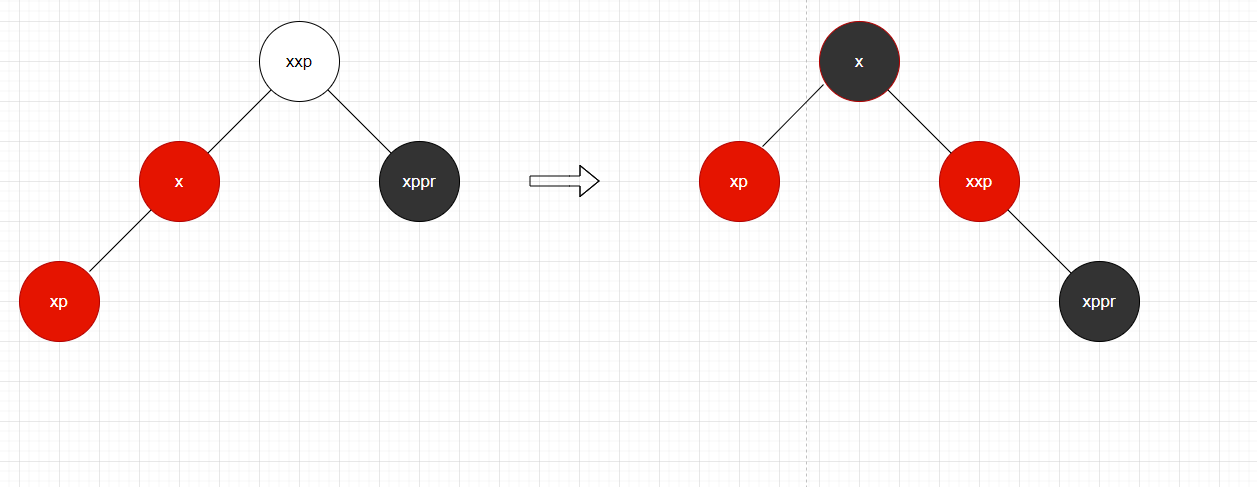
有了这些理解在去看putTreeVal方法就很简单了
1 | /** |
遍历树链,比较hash 大小,找到子节点插入位置,使用balanceInsertion方法平衡红黑树。
获取value get()方法分析
1 | public V get(Object key) { |
看下红黑树查找
1 | final TreeNode<K,V> getTreeNode(int h, Object k) { |
删除节点
1 | public V remove(Object key) { |
数组和链表删除还是比较简单的,下标指引变更即可。红黑树元素删除就相当复杂了,比插入数据要麻烦等多了
1 | final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab, |
简单说一下,这个方法代码是思路,首先处理最简单的链表删除元素,将链表中对象的引用改成旁边的元素。
红黑树删除元素则比较复杂点,考虑的情况比较多。比如删除节点在底下,没有子节点,就可以直接删除,最为简单了,红黑树的删除就是将复杂节点位置,变成简单的方式处理。这个方法大部分代码都是在处理左右节点不为空的情况,将删除节点位置和右节点下最左边的子节点交换位置,并且交换着色。为什么要这么做呢?主要是因为这个节点的hash值和删除节点值最为接近,红黑树的特性小于在左边,大于在右边,大于删除值的最小值,就整个红黑树最接近删除的值。在调整红黑树着色,任务就算完成了。
心得
整体来说HashMap的代码并不是很复杂,底层业务代码,其实就跟我们平常写的crud代码。但是我在看代码的时候,有一些地方好难看懂啊,主要是涉及到红黑树的知识点。很多程序员(包括我)平常都会抱怨数据结构没什么用,在工作中用不上,其实我们掌握不够熟练,在工作上不知道使用。